Diseño data warehouse: hechos y dimensiones; modelo estrella VS copo de nieve
En el diseño de un data warehouse hay que partir de una serie de características, como ponía en el artículo Introducción a los Data Warehouse:
- Administra grandes cantidades de información
- Guarda histórico de datos
- Condesa y agrega información
- Integra y asocia información de varias fuentes
Para ello, hay que cambiar de los modelos E/R usuales en los operacionales, ya que de tipo de modelo de dato es complejo obtener datos acumulados e históricos. Usualmente se realizan una serie de procesos ETL, para obtener un modelo multidimensional y así poder realizar consultas analíticas de manera más optima.
Normalmente las consultas de análisis, se realizan sobre un hecho esencial a partir de una serie de parámetros. Un ejemplo serían las ventas con una serie de variables como tiempo, localización y producto.
- Número de ventas en un periodo determinado
- Evolución de las ventas
- Previsiones de venta
- Productos más vendidos en una zona determinada
Este tipo de modelo de datos consta principalmente de dos tipos de elementos:
- DIMENSIONES: Representan factores por lo que se analiza un determinado área del negocio. Son pequeñas y usualmente están desnormalizadas.
- HECHOS: Son el objeto de los análisis y están relacionados con las dimensiones. Son tablas muy grandes y suelen estar desnormalizadas. Se a menudo incluyen diferentes agregaciones como máximo, mínimo, media, …
Los hechos contiene los datos de estudio y las dimensiones contienen los metadatos sobre dichos hechos.
Si la información necesita disponer de varios niveles de granularidad se crean jerarquías con las dimensiones. Por ejemplo la jerarquía fecha podría ser «día – semana – mes – trimestre – año».
Las jerarquías de las dimensiones presentan relaciones n-1 de manera que un valor de un nivel sólo puede ser agrupado por un único valor de cada nivel inmediatamente superior en la jerarquía. Esto facilita de manera rápida y sencilla el profundizar en el nivel de detalle (drill-down), disminuir el detalle(roll-up), selección (dice), proyección (slice) o pivotaje en las dimensiones (pivot), que son propios de los informes obtenidos a partir de data warehouse.
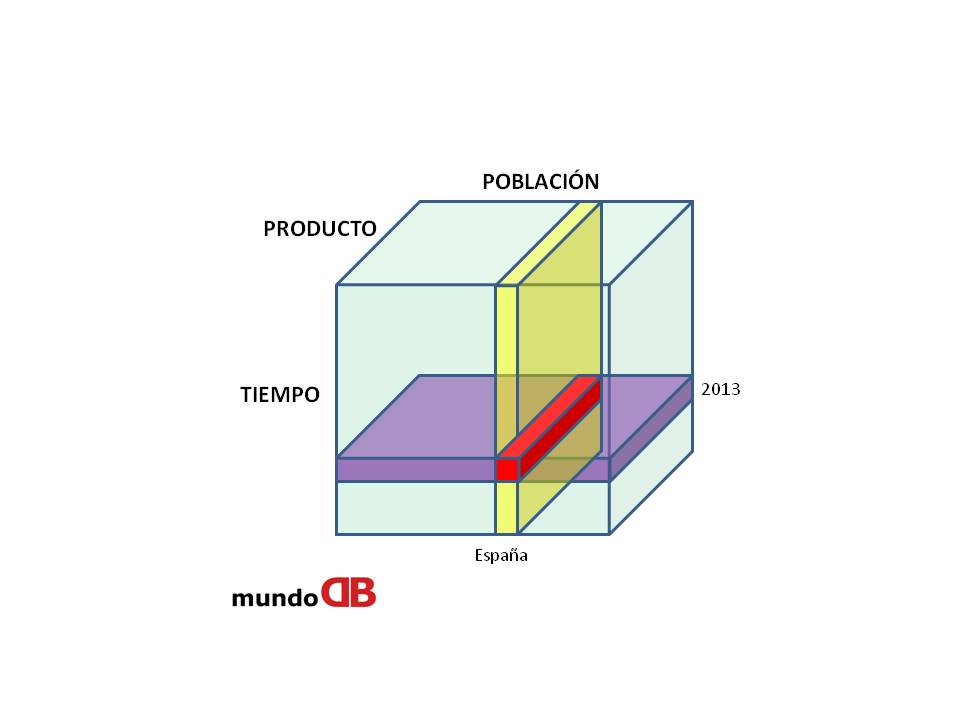
Diseño Datawarehouse: Cubo multidimensional
En una empresa de grandes dimensiones y sobre todo cuando hay múltiples data marts, es muy importante analizar las dimensiones previamente con las personas claves de las fuentes de datos, las personas claves de los datos finales y los diseñadores de otras personas involucradas en diseños corporativos de aplicaciones (data mart, generadores de informes, …), ya que las fuentes condicionarán los datos a proporcionar y las dimensiones se debería reutilizar en las distintas tablas de hechos de distintos data mart. Una dimensión tiempo debería de tener el mismo diseño en todos los data marts, porque si no cuando se integren será mucho más complejo. Es una decisión tanto técnica como política.
Los hechos deben de tener unidades de medidas uniformes: mismas localizaciones, unidades de tiempo o moneda, si no fuera así no se podría definir correctamente un hecho único.
Es importante no trabajar con claves significativas, para evitar problemas, por si existe cambios en el futuro, aunque esto habrá que valorarlo muy detenidamente, ya que podría perjudicar al rendimiento.
Un modelo multidimensional que no tiene jerarquías, se denomina modelo en estrella, si tuviera jerarquías, se denominaría modelo copo de nieve.
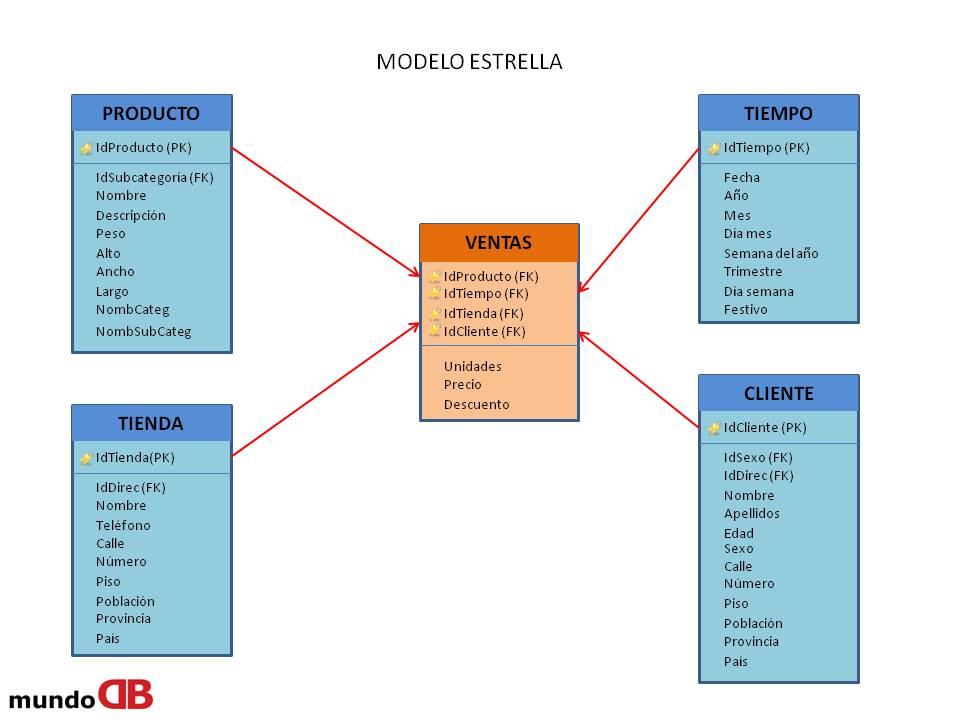
Diseño de un Data warehouse – modelo estrella (star schema)
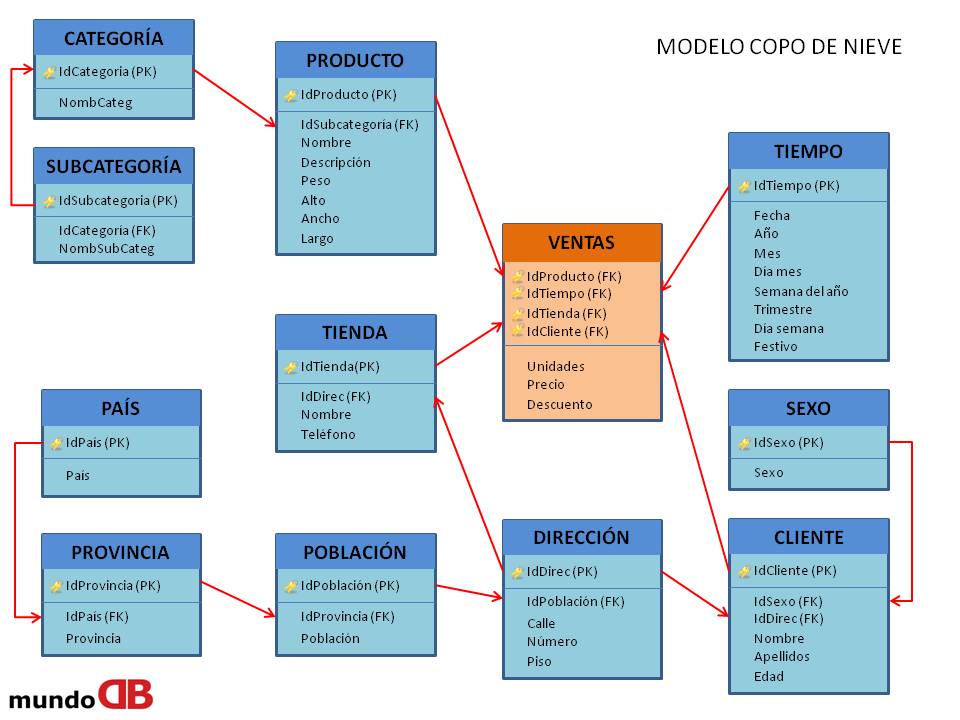
Diseño de Data Warehouse – modelo copo de nieve (snowflake schema)
Comments are closed.

